As you probably have heard, the Australian Census website was brought down by a simple DDoS attack last week. A DDoS attack can be generated today using a tiny sum of money, a stolen credit card number and any number of available stressor tools. The lesson here is to expect the unexpected and do your very best to plan for everything.
As a Canadian, you know how dear the census is to a large percentage of our population. Some consider it necessary boring paperwork, others consider it an “exciting thrill ride” to get the long form version, and some think it is an intrusion on privacy and should be (re)abolished. We are not here to make political judgement, but to point out that the excitement was so massive that when it was released that Statistics Canada’s website went down for a period.
Well, the good folks running the Australian census probably took note of this and built and tested a system capable of handling 200% of the reasonably expected traffic. Seems good, right?
What they didn’t count on was the massive growth in nuisance hacking in the form of DDoS attacks. As you probably have heard, the Australian census website was brought down by a simple DDoS attack this past week. A DDoS attack can be generated today using a tiny sum of money, a stolen credit card number and any number of available stressor tools. When it happens to high profile web applications, people go crazy on social media with jokes and speculation – and they sure did in Australia!
Just to set the record straight, it has been revealed by their chief statistician, David Kalisch, that it was a deliberate DDoS attack. However, not a lot of details were released. Why no details? Because it is smart practice to not reveal details about your network and its security because it just helps the next round of bad actors. However, it does lead to rampant speculation and chatter across the networking community including blaming the fault squarely on an application failure – and it is this kind of attention that the attacker is looking for.
Now let’s be honest – the application developers did expect an attack. Governments are attacked all the time and usually just when they are trying to do something high profile. But it appears that in this case they missed something and it got exploited.
The lesson here is to expect the unexpected and do your very best to plan for everything.
Delta computer systems strand thousands – when the unexpected happens
What is the lowest layer in the network stack? If you were thinking the physical layer then you get a point. As you add layers you add complexity meaning that one physical layer holds up (for example) two data layers that holds up four network layers, and so on and so on. We use words like electrical impulse, carrier and cables to describe it. Well, Delta learned that you also have to use the word, electricity.
They had a power outage that brought everything down with it. Why everything? Because systems are built on top of systems on top of systems.
CBC did a fantastic write-up on the need for redundancy as it related to Delta with the absolute best quote of the week attributed to Srinivasan Keshav, professor of computer science at the University of Waterloo:
Failures are not exceptions. Failures are kind of normal.
The solution is to have multiple power options, located in different places, connected with different wires, and run with different technology. This solution applies all the way through the IT stack as it relates to power, networking, hardware, and software.
Let’s take our own organization as an example. CIRA doesn’t sell or deliver incredibly complicated software applications or keep planes up in the sky, but we do run a critical part of the DNS for over 2.4 million .CA domain names. If we fail that is a lot of websites that have problems – including those that do deliver complicated software and those that do keep physical infrastructure running.
How do we do it?
Remember the lesson discussed earlier about not releasing details about your systems? We don’t talk about our systems lest we help to arm the bad actors, but suffice to say that we spend every waking minute thinking about every little thing that can fail and do our best to mitigate the risk because parts of system do fail and when they do, we want to try our best to limit the impact.
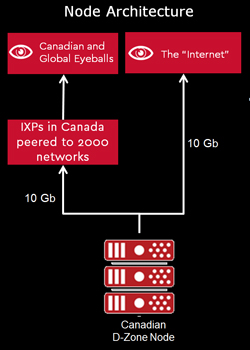
What we can illustrate is how we take this approach with our own secondary DNS service, D-Zone Anycast DNS. Not only do we maintain nodes around the world, each node has two different transit providers, each node has server redundancy and power redundancy, and we have multiple clouds. Anycast technology (and the DNS in general) also has some built in redundancy because it keeps the Internet working.
The lesson for IT managers – and frankly anyone in an organization – is that failures are normal. The good news is that in a cloud service world there are a lot of cost-effective services that can help you minimize their impact because you are getting a massive level of redundancy without requiring your own investment in hardware, networking, and even electricity.
Rob brings over 20 years of experience in the technology industry writing, presenting and blogging on subjects as varied as software development tools, silicon reverse engineering, cyber-security and the DNS. An avid product marketer who takes the time to speak to IT professionals with the information and details they need for their jobs.