Part 1 of a series of pieces on DNS encryption. Read part 2: DNS over HTTPs (DoH) – Who do you love?
If this is true then how did we get here?
First a quick primer on the domain name system (DNS). When a user or application uses the DNS to visit a website or web service they first ask where it is located using a recursive DNS resolver. For most Canadian Internet users, this resolver is located on the network of the internet service provider’s and it is not something a user thinks about. If the recursive resolver doesn’t know the information, or if it “decides” that the information it has is too old, then it starts the process of looking up the data. This starts by querying “the root,” then traverses the DNS hierarchy down to the top-level domain manager, and finally the domain holder (here is a video for those visual learners)
In this process the recursive resolver asks what are called, authoritative DNS resolvers what they know for each element of the domain name. A good metaphor is that the recursive resolver has the Internet’s map, and for things it doesn’t have, it knows how to look it up. Fundamentally, the DNS is made up of two things: recursive and authoritative resolvers.
This system is based on Internet Engineering Task Force (IETF) RFC1034 and 1035, which were originally proposed in 1987 and are standards.
(As a side-note an RFC, or “Request for Comment” is a technical document submitted to the Internet Engineering Task Force (IETF). The entire global technical community can then contribute to it. Some RFCs go on to become “internet standards.” If you want to know how that sausage is made then go here.)
What is important is that DNS queries are sent in clear text over the wire. And this is at the root (no pun intended) of what many think is the problem. It is based on the concept of a free and open Internet and that concept is under threat because bad actors (i.e. hackers) can take advantage of it, while the data can also be used in ways that the end user may not want from commercial entities and governments.

The privacy revolution
While history is more nuanced, suffice to say that back in 2013 Edward Snowden asked the IETF to build, “an internet for users, not spies.” And in July of 2013 the IETF Internet Architecture Board (IAB) formally recognized the privacy consideration. The timeline looks like this:
- July 2013 – Privacy considerations for internet protocols RFC6973
- May 2014 – Pervasive monitoring is an attack RFC7258
- August 2015 – Confidentiality in the face of pervasive surveillance: A threat model and problem statement RFC7624
- March 2016 – DNS query name minimization to improve privacy RFC7816
- May 2016 – Specification for DNS over transport layer security (TLS) RFC7858
- December 2018 – DNS Queries over HTTPS (DoH) Internet Draft NWG (draft-ietf-doh-dns-over-https-12)
Today, we have DoT, DoH and DNS query name minimization with architectures that look like these diagrams:


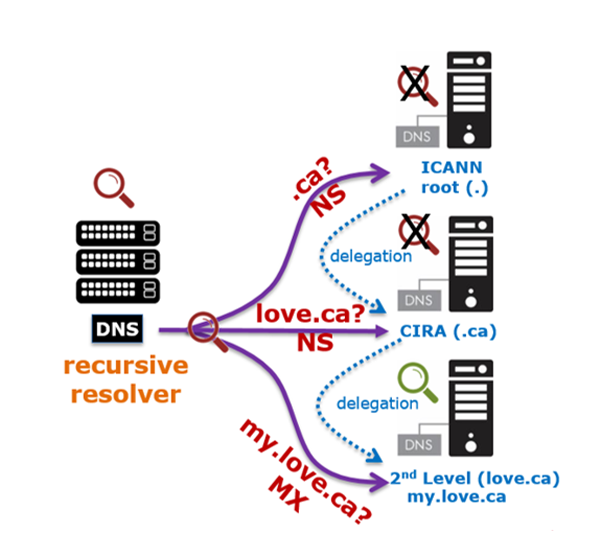
DNS query name minimization involves asking each authoritative server only the question you need to have answered by its part (e.g. asking the root, “where does .CA live?” and not, “where does “love.CA” live?”). The result is that the minimum amount of data is requested. This sounds obvious, but within the DNS you can (and often do) keep the file information shared at all layers. With query name minimization, as the query travels from server to server, anyone intercepting the package along the way will not know the full answer nor the original querier. It is arguably the smaller part of privacy – but still useful.
Where things get more interesting is the difference between DoT and DoH. This includes which is better and even whether these standards relegate other standards like DNSSEC to the dustbin of history (hint – they probably don’t). There is much to unpack here but we aren’t going to….yet.
This little historical primer is part one of a multi-part series on DNS encryption. We’ll cover the players, the standards, the security risks, and the commercial adoption. It is moving very quickly, so we will know exactly what we cover when we do. For instance, when I woke up this morning I didn’t expect Microsoft (using a blog, of all things) to announce their intentions for Windows to support DoH. Things are happening fast in a world where standards usually move slowly. What we know for sure is that for the first time ever, what is common knowledge at CIRA is now a global fact – the DNS is one sexy beast.
We started with a quote from APNIC, so we will end with one from Geoff Huston to give you an idea of what is to come, where we might stand, and what we are doing about it.
“It’s easier to sustain a case that DoH has the potential to change the parties whom you bring into your trust circle….and not necessarily in a good way.”
Rob brings over 20 years of experience in the technology industry writing, presenting and blogging on subjects as varied as software development tools, silicon reverse engineering, cyber-security and the DNS. An avid product marketer who takes the time to speak to IT professionals with the information and details they need for their jobs.





